Glossary¶
Estimator¶
An estimator is any object that learns from data. Most typically these are classification, regression and clustering algorithms.
See the Scikit-Learn estimator.
Model¶
What exactly is a model? In MyAutoML we view a model as something that we can apply to data to make predictions.
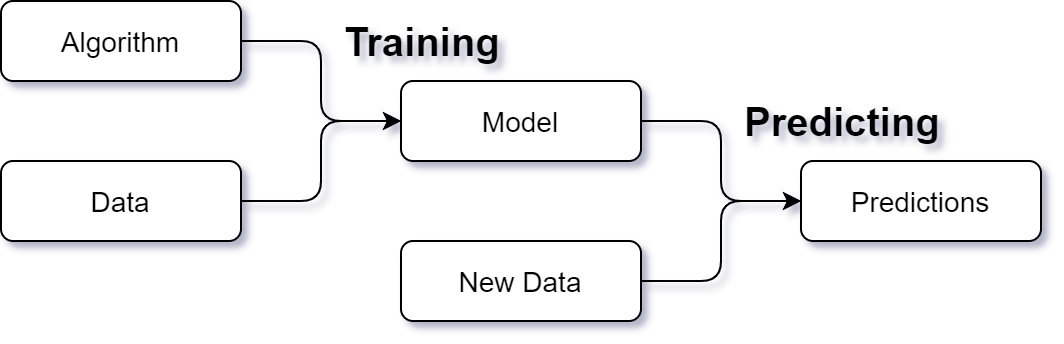
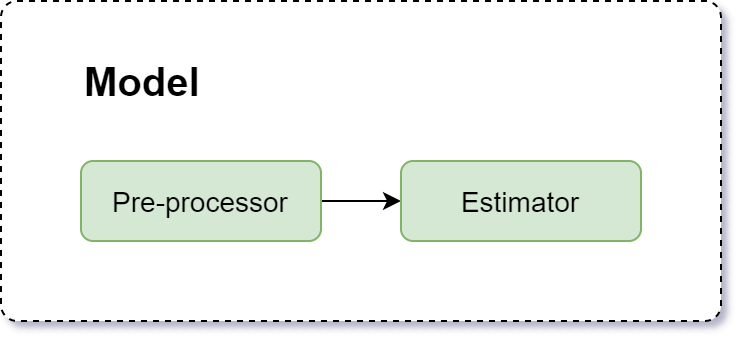
Normally the raw data we start off with requires some preprocessing, before it can be used as input for the prediction algorithm (see the training and predicting processes above). Therefore we view a model as a Pipeline containing a preprocessor and an estimator:
Model Registry¶
A model registry is a tool to keep track of your models. Ideally it serves both as a log for your data science experiments (keeping track of all the variations of models you’ve trained, along with key metrics indicating model performance), and as a store for serving models to prediction processes.
MLflow has modules supporting these functions, namely the MLflow Tracking Server and the MLflow Model Registry respectively.
Pipeline¶
A pipeline is a sequence of operations to be carried out on a dataset.
See the Scikit-Learn Pipeline.
Pre-processor¶
A pre-processor is any object that transforms a raw data set into a form that can be used with an Estimator. A pre-processor often takes the form of a Pipeline containing multiple transformation steps.
See for example the Scikit-Learn ColumnTransformer and the Scikit-Learn preprocessing module.